Cómo diseñé el backend de nuzur (y qué cambiaría)
Hace tres años, el plan era solo un boceto en un cuaderno, hoy es un sistema real en producción. Te llevo a través de la arquitectura real detrás de nuzur, capa por capa. Y al final, comparto cuatro cosas que cambiaría si empezara de nuevo.
Mira la versión en video aquí:
Contexto rápido
nuzur es una herramienta visual de modelado de bases de datos. Diseñas tu esquema como un diagrama — tablas, campos, relaciones — y nuzur genera las partes aburridas: las migraciones SQL, las operaciones CRUD, las operaciones de listado, todo el módulo de gestión de entidades en Go. Tú escribes tu lógica de negocio encima de eso.
Toda la filosofía es model-first. Tu esquema es la fuente de verdad, y todo lo que viene después se deriva de él.
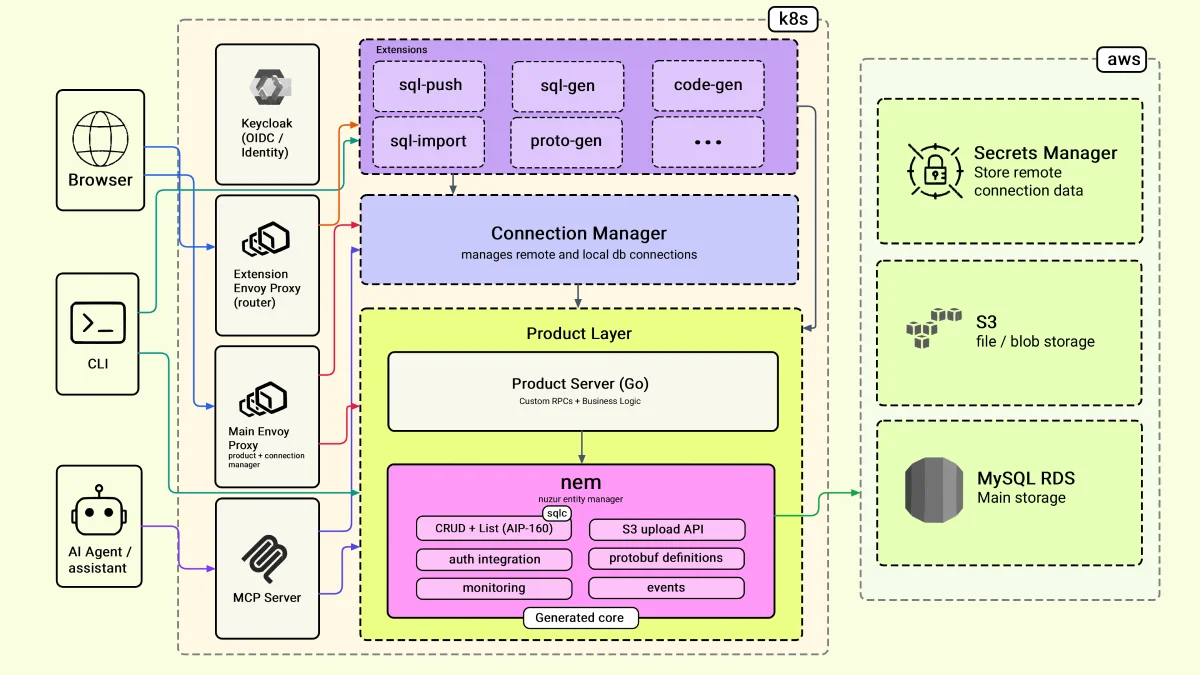
Aquí está el sistema de un vistazo. Lo recorreremos capa por capa, y para cada una te diré qué elegí, por qué, y qué cambiaría.
Capa 1: El edge
Estos son los componentes con los que el usuario final interactúa directamente.
La aplicación web
La app web está en React. Lo primero que sorprende a la gente es usar gRPC con el navegador. Los navegadores no entienden gRPC de forma nativa, así que hay una capa de traducción en el medio: Envoy. Envoy traduce de gRPC nativo a gRPC-Web, que el navegador sí puede consumir.
Suena exagerado — y es un trade-off — pero la ventaja es una definición IDL consistente en todas las capas. Tengo un único protobuf en la capa de producto, y es el mismo que uso en el frontend. Mantiene todo coherente.
La herramienta CLI
La CLI está escrita en Go. Uso una librería llamada urfave/cli, que es directa y te da todo lo que necesitas sin demasiado ceremonial. Como la CLI también es Go, puedo hacer mis llamadas gRPC directamente — sin capa Envoy aquí.
Uso GoReleaser para empaquetar la CLI en binarios para diferentes sistemas operativos.
La CLI habilita un par de cosas que la app web no hace. Los usuarios pueden ejecutar extensiones y generar código directamente en su sistema de archivos local. También pueden abrir una conexión WebSocket desde su máquina al backend de nuzur para conectarse a una base de datos local para pruebas.
Agentes de IA y el servidor MCP
Esta es la forma más nueva de interactuar con nuzur. Agregué un servidor MCP — piénsalo como una capa de traducción, el mismo rol que juega Envoy para la capa web, pero para asistentes de IA.
El servidor MCP está escrito en Go usando el SDK oficial de Go. Envuelve las acciones de nuzur como herramientas y las expone a través del protocolo MCP estándar.
La parte con la que más luché fue la autenticación. En el navegador, tienes un token almacenado localmente. En un contexto MCP, no hay navegador — así que tuve que gestionar el seguimiento y la reemisión de tokens del lado de nuzur. Me llevó un tiempo hacerlo bien, pero una vez en su lugar, agrega funcionalidad muy útil: los usuarios pueden interactuar con sus proyectos de nuzur directamente a través de Claude o cualquier asistente de IA compatible con MCP.
Puedes encontrar el conector MCP de nuzur aquí.
Capa 2: El núcleo generado y la capa de producto
Hay un malentendido común sobre la generación de código: ¿no se sobreescribirá mi código cada vez que regenere?
La forma en que manejo esto es la decisión arquitectónica más importante en nuzur. Déjame explicarlo.
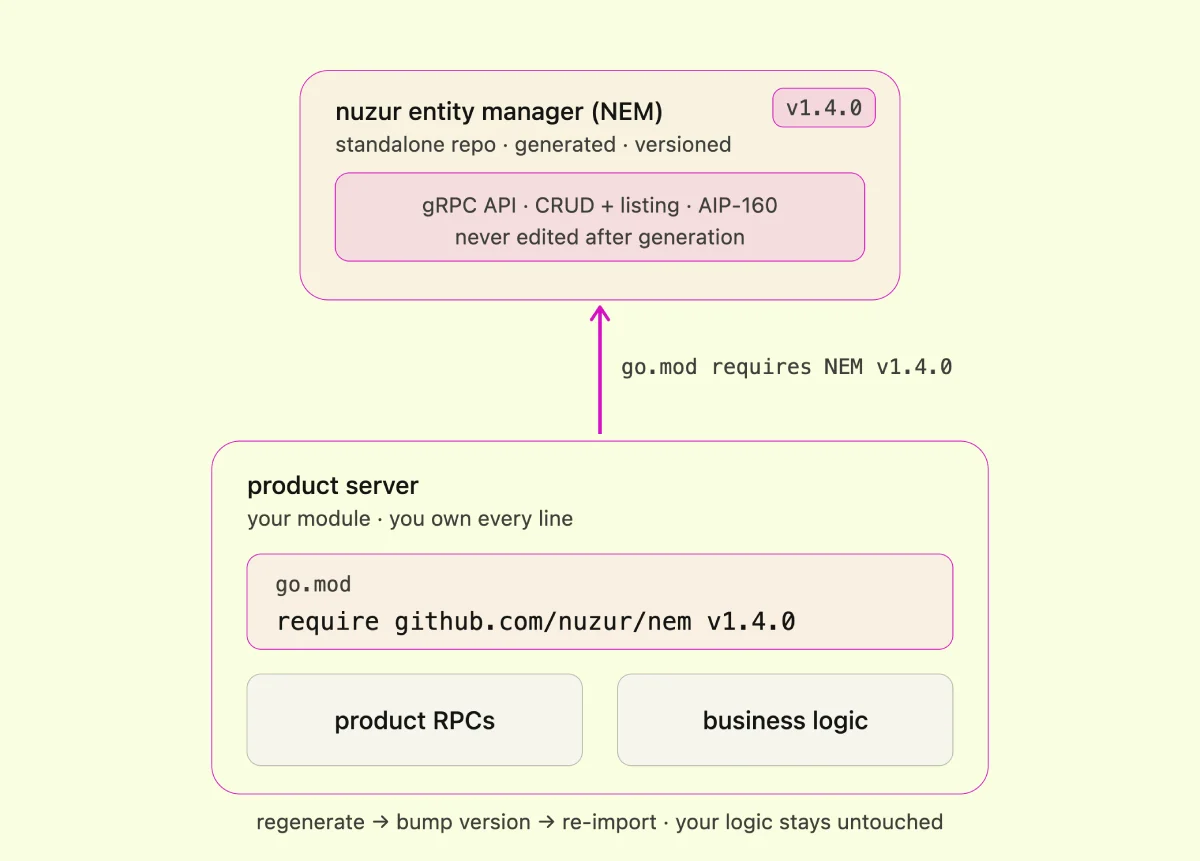
nuzur genera un repositorio llamado NEM — el nuzur Entity Manager. NEM es un módulo Go independiente y versionado en su propio repositorio. Contiene todo el código generado: las definiciones de la API gRPC, todas las operaciones CRUD y las operaciones de listado (con filtrado AIP-160 integrado).
La clave: nunca toco NEM directamente. Lo incluyo en mi servidor de producto como un módulo Go, igual que cualquier otra dependencia. En el servidor de producto, defino mis RPCs de producto reales — los que son míos — donde vive mi lógica de negocio real. NEM y el servidor de producto nunca comparten un solo archivo.
Cuando mi modelo cambia, regenero NEM, incremento la versión, lo importo al servidor de producto y sigo adelante. Mi lógica de negocio queda intacta.
La única regla: una vez en producción, no hagas cambios que rompan la compatibilidad. No elimines campos que ya estén en uso. Solo agrega al final. Eso mantiene todo compatible hacia atrás.
La filosofía es: genera el núcleo, escribe a mano (o con IA) el borde.
El gestor de conexiones
El gestor de conexiones es un módulo separado — intencionalmente. Maneja todas las conexiones abiertas a bases de datos y máquinas locales, por lo que consume más recursos que el resto de la capa de producto. Lo mantuve separado para que pueda escalar de forma independiente si y cuando nuzur crezca.
Capa 3: Extensiones
Las extensiones son donde ocurre la generación real. Cada extensión vive en su propio pod y expone su propia API. El núcleo orquesta; las extensiones hacen el trabajo.
¿Por qué este diseño?
- Aislamiento. Un pod puede fallar, redesplegarse o comportarse de forma impredecible — nada de eso impacta al producto. Esa era mi principal preocupación al diseñarlo.
- Escalado independiente. Una extensión puede consumir muchos más recursos que otra. Ejecutarlas por separado significa que puedo dimensionarlas de forma independiente.
- Flexibilidad de lenguaje. Como el límite es una API, las extensiones pueden estar escritas en diferentes lenguajes. La puerta está abierta.
Capa 4: Auth
No construí mi propio servidor de autenticación. Uso Keycloak, un proveedor de identidad de código abierto que maneja el login, la emisión de tokens y la gestión de usuarios. Es compatible con OIDC, por lo que integrar Google o GitHub login es directo.
La decisión fue simple: construir un servidor de auth realmente bueno es un proyecto complejo y arriesgado. Keycloak está bien mantenido, tiene una comunidad activa y maneja casos borde en los que no quiero pensar.
Sí viene con trade-offs, que cubriré a continuación.
Capa 5: Despliegue
Todo corre en Kubernetes, y uso Helm para el empaquetado y despliegue. Helm te permite mantener todas tus configuraciones en tu repositorio Git — qué imagen usar, qué recursos, todo rastreado y versionado. Lo encuentro extremadamente útil.
Para los datos:
- Base de datos: MySQL en AWS RDS — confiable, maneja backups y failovers, bajo costo para empezar
- Almacenamiento de archivos: AWS S3
- Secrets: AWS Secrets Manager
Mi cluster de Kubernetes corre en Linode (Akamai Cloud), mientras que mi base de datos está en AWS. La razón fue el costo — Linode tiene precios mejores y más predecibles. Pero como verás en la siguiente sección, eso tuvo un costo real propio.
4 cosas que cambiaría
1. gRPC en la web
No me arrepiento del resultado — tener definiciones proto consistentes en todas las capas es limpio y vale la pena. Pero configurar gRPC-Web con React fue genuinamente doloroso. Pasé varios días luchando con ello antes de la era de la IA, haciendo todo a mano. Seguiría eligiéndolo, pero lo haría de forma diferente, e imagino que ahora es más fácil de configurar.
2. Dos nubes diferentes
Correr Kubernetes en Linode y la base de datos en AWS tenía sentido por el costo, pero introdujo latencia que no anticipé. Tuve que hacer mejoras compensatorias, y lograr que RDS funcionara correctamente fuera de su VPC fue una lucha de varias horas.
Si empezara de nuevo: mantendría todo en una sola nube el mayor tiempo posible. Es más simple, más rápido y evita toda una clase de dolores de cabeza de infraestructura.
3. Keycloak
Keycloak ha funcionado. Pero ha sido difícil de personalizar. Si quiero cambiar algo — como simplificar el formulario de registro — tengo que escribir un provider en Java. También consume más recursos de los que esperaba para lo que hace.
Exploraría alternativas. Algunas cuestan dinero, lo cual Keycloak no, así que es un trade-off real. Pero al menos evaluaría las opciones con más cuidado antes de comprometerme.
4. Un pod por extensión
Sigo creyendo en la idea — el aislamiento y el escalado independiente son beneficios reales. Pero creo que lo implementé demasiado temprano. Empezando de nuevo, correría todas las extensiones en un solo pod y las separaría solo cuando fuera necesario. El overhead de gestionar pods individuales — especialmente mantener una librería compartida sincronizada entre todos ellos — se acumula. Ganaría esa complejidad en lugar de empezar con ella.
Resumen
Aquí está el stack completo de un vistazo:
- Frontend: React + gRPC-Web
- Proxy: Envoy (traducción gRPC-Web)
- CLI: Go + urfave/cli + GoReleaser
- Capa de IA: servidor MCP en Go
- Núcleo generado: NEM (módulo Go versionado, gRPC + CRUD + AIP-160)
- Servidor de producto: Go (lógica de negocio, RPCs de producto)
- Extensiones: Go, un pod por extensión
- Auth: Keycloak (OIDC)
- Despliegue: Kubernetes + Helm en Linode
- Base de datos: MySQL en AWS RDS
- Almacenamiento: AWS S3
- Secrets: AWS Secrets Manager
Los cuatro arrepentimientos — la complejidad de configurar gRPC-Web, la latencia de la nube dividida, la rigidez de Keycloak y el aislamiento prematuro de extensiones — son cosas que seguiría eligiendo con más información. Solo vienen con un costo que querría tener en cuenta antes.